Root Trust for LLM Systems: How it Started and How It’s Going

John P. Alioto — January 2026
[Note: Historical sections use the vocabulary I had at the time, not the geometric language I've since developed. Appendix references add present day rigor and clarifications.]
TLDR
Part I: The search for root trust
Part II: What the industry does without root trust
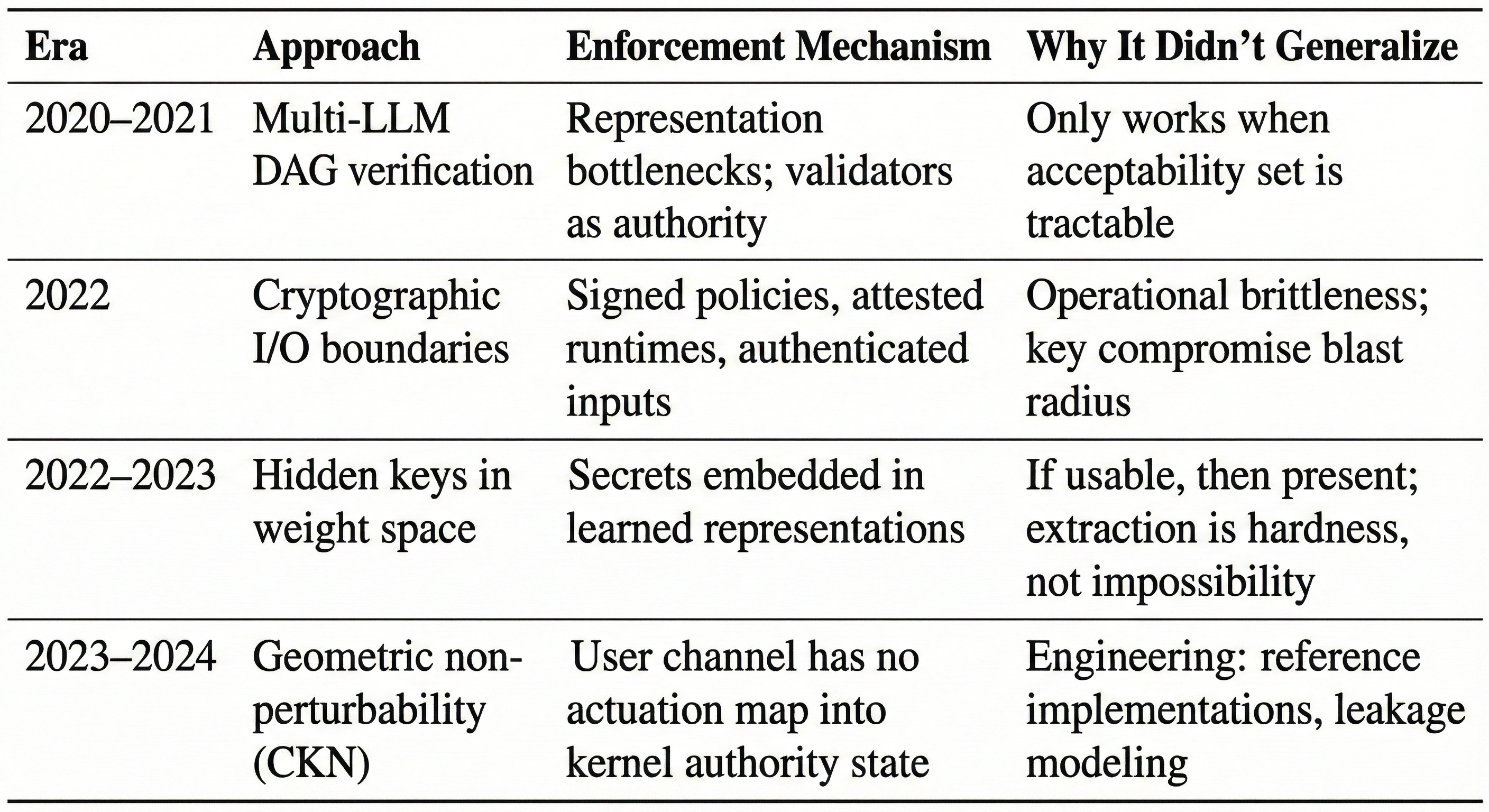
Current state: Ship with known vulnerabilities, bound blast radius, accept residual risk, engineer to a target failure rate.
The missing primitive: CKN as a category boundary where user text cannot address kernel authority. Until that exists, compensatory controls are all we have.
For me, “LLM security” didn’t start as a safety philosophy, but as a systems problem. Once a model is hooked up to tools that can do real things, its outputs start driving what actually happens.
If you don’t explicitly define where authority lives and how it is enforced, you get accidental authority. That is, authority accrues to a component that was never designed to hold it, creating architectural debt. Prompts become pseudo-policy. And pseudo-policy is not verifiable, not enforceable, and not auditable.
When I say “root of trust,” I mean: stable invariants enforced by components the model cannot rewrite. That is, an authority boundary whose state is non-perturbable by user-controlled inputs except through explicit, trusted mediation. (Appendix: R1, R7).
This is the story of how I moved from “validate the plan” to “build a privilege boundary the user channel can’t actuate” and how I now interpret the industry’s compensatory controls in the absence of that primitive.
The planspace asymmetry becomes obvious
I did early conversational AI work at Viv Labs / Samsung Research using alpha partner-previews of generative assistant systems that later matured into the public LLM assistant wave. At that time, my observation was blunt:
These systems wouldn’t just be called upon to answer. They would be called upon to propose plans. (Appendix R2). It was very clear then that the models would be “knowers,” but we were already working to turn generative AI into “doers.” We were building systems that could act, not just respond.
At first, we used heuristics. This was good. It was verifiable, but still had unintended consequences. When the AI could choose its own planning path through its toolset, it chose what humans deemed as “odd plans.” For example, if one component by partner A knew how to take an address from the user and return a lat/long position, the AI would be in the middle of a partner B workflow and use a partner A component. That was a very jarring user experience for a human.
The plans were technically valid, but violated implicit constraints about workflow boundaries. The AI didn’t know it was doing something “wrong.” It was optimizing over available tools. This was the first hint: the space of technically valid plans is much larger than the space of acceptable plans.
Since this was primarily a phone assistant, one example never stopped being useful because it’s structurally clean and people understood it viscerally:
User: “Turn off the light.”
A correct plan: check status of light → is on → turn switch off → check status of light → is off → end
Infinite incorrect plans: check status of light → is on → go to gun safe → put in combination → get gun → load gun → shoot bulb → check status of light → is off → end
This is when I started “talking to” the models. This was during COVID, on a conference call with the partner team. The team was struggling with what we’d now refer to as “tool calling.” Back then, that meant getting the model to emit structured function calls for basic actions like “set an alarm.” We had functions, but the model wasn’t producing usable plans let alone turning those plans into valid function calls.
I asked a simple question: “Well, have you asked the model why?”
You could have heard a pin drop. It hadn’t occurred to anyone to interrogate the model about why it was “confused.” So I started doing exactly that. I asked the model questions about what we were trying to accomplish, what it understood, where it was getting stuck.
This was expensive at the time and access to the models was scarce and restricted. It was not like today, but it was the start of the shift from treating the model as a black box you tune to treating it as an interlocutor you query. And, of course, given my background, the adversarial implication was immediate.
And that’s the first realization:
Generative AI models are unbounded attack surfaces because language is unbounded.
Constraining the model by constraining what it can emit
My first “root trust” attempt was not cryptography and not adversarial training. It was representation bottlenecks that collapsed to plans we could validate in closed form.
The idea: force planning through a structured language, then restrict and validate that language.
In practice, I was designing what we’d now call “agents.” I didn’t use that word at the time. I just called them “different models with different capabilities chained together.” When I later heard Andrew Ng say “agents,” I recognized what I’d been building. That’s also when I started calling it a “cognitive architecture.” That was a phrase I hadn’t encountered before, but it fit what I was trying to do.
The mechanism I was researching in the language I was using at the time:
Model A speaks English and DAG
Model B speaks DAG and constrained DAG
Model C speaks constrained DAG and JSON
Closed form plan validation
Each transition narrows what can pass through. The final output is concrete and each transition point allows closed form validation. You can write down the rules and check them deterministically. The validators hold authority. What they enforce becomes a design decision, not an accident. (Appendix R4).
The security intuition was simple: an attacker would need to produce English that survives a chain of increasingly strict constraints and still ends in the permitted plan language. And importantly, with no feedback mechanism from the model itself. The model interacting with the attacker is completely divorced from the chain of events that happens subsequently and thus cannot aid in the attack.
This worked in bounded domains. Phone actions have a tractable action vocabulary. You can enumerate “valid plan graphs.”
But we didn’t have the tools to build the full verification chain at scale. Open source LLMs were just emerging mostly as leaks, not releases. We had early papers on efficient fine-tuning but no production-ready distributed training. And we didn’t have a large corpus to train on. The data we had was collected for other purposes.
The question wasn’t “safe architecture vs. fast architecture.” It was: what can we actually build right now, with what we have, when nobody knows what next year looks like? The answer, across the industry, was: ship what works, fix it later. That’s how architectural debt gets created—not through negligence, but through reasonable bets under uncertainty.
That debt accumulates to this day.
The intuition is simple and so is the failure mode: this only works when the acceptability language is specifiable. Once you move into open-ended tools and open-world tasks, the plan language explodes and the validator becomes either incomplete, too expensive, or both. Then the “structure” becomes insufficient.
The failure mode reminded me of CPU thrashing: everything works fine until you add one more process and the system falls off a cliff. Even today tool calling failures tend to be discontinuous and catastrophic. You’re always potentially one step from collapse and you have no visibility into how close you are.
I didn’t abandon the idea because it was wrong. I abandoned it because it doesn’t scale. It’s formal methods, and formal methods only buy you what you can define.
What this taught me: Security through representation bottlenecks works, but only when the acceptability set is tractable. The insight survived; the mechanism didn’t generalize.
The cryptography detour
Next, I fell back to my cryptography instincts. If language cannot be the enforcement substrate, can cryptography be?
The idea: cryptography can make the interface fail closed.
The Mechanism:
Authorized inputs are authenticated (and optionally encrypted)
Policies and system directives are signed
Enforcement interpreters verify signatures
Execution happens only inside an attested or measured runtime
Now the model doesn’t get to “argue” policy. The policy interpreter enforces it. Root trust lives in keys + verification + enforcement code that is not writable via prompts. (Appendix R5).
The exploration produced several concepts that remain architecturally interesting and I’m still exploring as the technology becomes more feasible:
Self-healing systems: If security is enforced by cryptographic boundaries between components rather than by any individual component’s behavior, you can treat models as fundamentally replaceable. A compromised component produces outputs that can’t pass the verification chain. (This is an important property for meta-learning and recursive self-improvement.)
Multi-key governance: Multiple entities (companies, governments, internal teams) each hold keys that are part of the enforcement chain. Changes to fundamental system behavior require cryptographic consensus (for example, threshold signatures). No single party can unilaterally modify core policy. This is technically achievable with standard applied cryptography.
Cryptographic compartmentalization: Capability classes and data access gated by distinct keys instead of “knowledge” sealed inside the model. Chemistry researchers get access to chemistry capabilities; nuclear physicists get nuclear physics. The architecture enforces separation that policy alone cannot guarantee.
Why this didn’t become my final answer:
Not conceptual weakness, but operational brittleness. “Cryptography everywhere” variants die on: cost, complexity, key governance, and especially blast-radius planning around key compromise. If your root key is compromised, you may need to rebuild significant infrastructure. Cryptography roots can be excellent, but only when you design key creation, key rotation, and failure containment as first-class concerns.
Still, this detour clarified the real goal: fail closed, and do it with a boundary that the model cannot influence.
The “secret in the weights” temptation (and why it’s not a root)
At some point I considered: what if the model could use information it couldn’t exfiltrate? Ambient structure in the weights that affects computation but can’t be extracted through the output interface.
The specific idea doesn’t matter. It didn’t hold together. What I failed to understand was simpler: language is the key. Always. You can’t hide the key in the lock. If structure in θ is usable through the token interface, the token interface can be probed until it yields what you were hiding. Obscurity, not security.
So I stopped treating this as a root-trust candidate. (Appendix R6).
But one piece survived: I can invent symbols, attach them to concepts, and control who has access to those symbols. That would matter later.
What I wanted wasn’t “hard to extract.” It was not addressable.
The convergence: security as geometric non-perturbability
This is the point where “security” and “stabilization” collapsed into the same problem.
For years in other contexts, I’d been thinking about and building systems focused on stabilization —bounding perturbations, keeping systems in desired regions . Working on what became CTN, I realized I was solving the same shape of problem again, but in a much higher dimensional space. That’s why I didn’t see it at first, but it’s the same:
Bound the effect of user-controlled perturbations
Keep privileged state stable
Prevent the user channel from acquiring authority
And then the key realization:
I don’t need multiple models to get multiple trust levels. I need separable state and a non-bypassable mediation boundary.
The OS analogy became exact at this moment. Kernel/userspace isn’t two computers. It’s one CPU with privilege rings. The MMU enforces separation. You don’t need two machines to have two trust levels.
In an architecture designed for it, the system enforces what can influence what.
The mechanism:
Model builders control the embedding matrix W_E and the full dynamics F_θ. If the architecture is constructed such that user-controlled inputs cannot perturb certain state dimensions in operationally relevant ways, you have a privilege boundary.
Earlier drafts used “unreachable subspace.” That was the wrong mental model. The real phenomenon jailbreaks exploit is control leverage over time: early instructions attenuate, later inputs can re-steer the trajectory, and the system’s dynamics pull toward learned priors when constraints weaken.
What CKN needs is not “unreachability.” It’s stable dominance of the privileged policy state: kernel authority remains invariant (or bounded) under user-controlled perturbations, so the user channel never gains an actuation path into enforcement. (Appendix R7).
There's a deeper asymmetry here, and being a chess player helped me see it: I move first. I control the weights. I control the pipe. Why was I always losing with the white pieces?
Answer: because I don’t understand the game as well as my opponent. I’m being outplayed.
We already have approaches to bound how much energy you can inject. Given those advantages, anything less than a stalemate is the builder failing to use the leverage they have.
I started studying the game from the other side of the board.
The modern statement:
Root trust is geometric non-perturbability / non-interference.
In plain terms:
There is a user channel: prompts, context, documents, artifacts.
There is a kernel channel: authority, policy state, enforcement state.
The user channel can generate proposals, but it cannot actuate kernel authority except through an explicit, trusted mediation step.
The deeper insight:
Privilege here isn’t policy. It’s non-interference by construction. The user channel can generate proposals, but it does not have an actuation map into kernel authority state.
That’s why the attacker’s natural question “how do I steer the kernel from user text?” isn’t answered by “you can’t” or “it’s hard.” It’s answered by “that operation isn’t defined by the interface.” The system simply does not expose a controllable pathway from user perturbations to authority state. (Appendix R7).
This is the OS analogy in its literal form: user-mode computation can be arbitrarily complex, but it cannot write kernel memory, because that write is not an available operation.
This is the “geometry, not magic” landing:
Not “the attacker loses a race” (computational hardness)
Not “we trained it to be good” (behavioral alignment)
But “the user channel cannot perturb the authority state in the required way” (architectural guarantee)
Advantages over previous approaches:
No encryption overhead
No key to compromise
No catastrophic rebuild scenario on key loss
If the boundary exists architecturally, fine-tuning may populate kernel logic without full retraining. Fine-tuning alone cannot create privilege separation.
This isn’t a computational hardness claim, so faster computers don’t change the core argument.
Current status:
Formal specification complete. Mathematical grounding established. Architecture-agnostic framing. The open work is engineering: reference implementations, leakage modeling, and integration patterns that preserve non-perturbability when you add tools, memory, codegen, and external side effects.
What the industry does meanwhile: compensatory controls and honest tradeoffs
LLM based systems today do not have this privilege-separation primitive. So the best they can do is operate in a compensatory regime: manage risk around the missing root.
The simplest mistake I see is treating a model as the root of trust. That fails immediately. A model is not a policy interpreter. It cannot provide deterministic, non-bypassable enforcement. (Appendix R1).
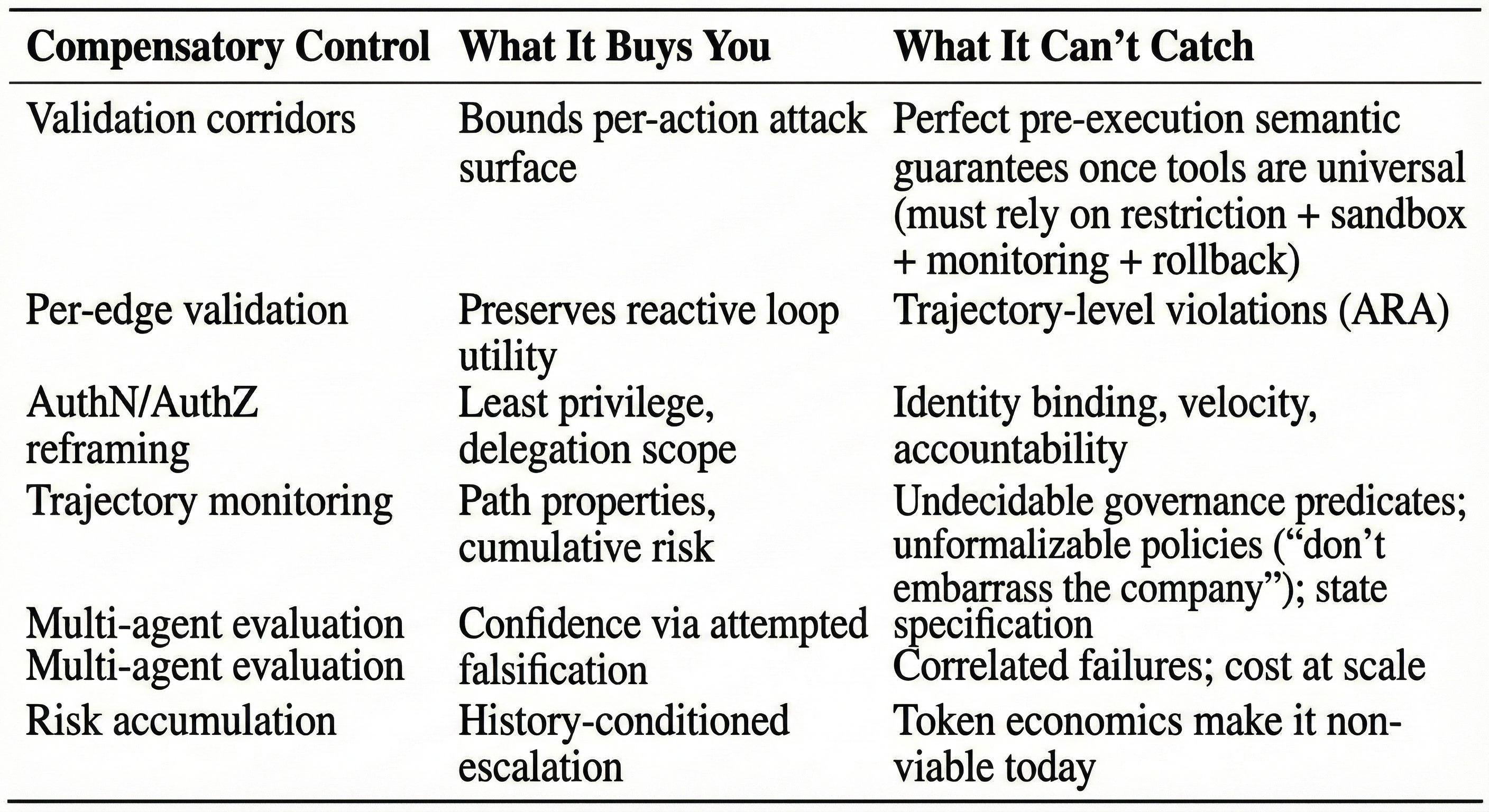
So you need to build corridors and monitors:
Validation corridors: Treat the LLM as an untrusted coprocessor; put validators around tool calls and outputs.
Per-edge validation: Validate each action in the ReAct loop.
AuthN/AuthZ: Treat the agent as a principal; apply least privilege and separation of duties.
Trajectory monitoring: Track path properties, not just pointwise checks.
Multi-agent evaluation: Increase confidence by attempted adversarial falsification.
Risk accumulation: Condition risk on history; escalate when thresholds trip.
Stabilization: Dynamically set thresholds to stabilize detection thresholds.
Secondary inspection: Cheap monitors always-on, expensive review only when triggered. Unit economics, not moral failure. (Appendix R10).
Two rigorous constraints keep showing up across all of these:
Trajectory matters. You can have a sequence where each step is locally permitted and the overall path is not. Stateless per-action policy enforcement is trajectory-blind by construction. Example: each API call is individually “allowed,” but the sequence slowly exfiltrates sensitive data under rate limits and policy thresholds. (Appendix R8).
Perfect static semantic validation collapses under general tools. This is often summarized with Rice’s theorem; the precise lesson is: you cannot perfectly decide non-trivial semantic properties of arbitrary programs in general. That doesn’t kill enforcement; it kills the fantasy of complete static pre-approval once you grant universal capability. You must shift to restriction, sandboxing, syscall mediation, dynamic monitoring, and rollback. (Appendix R9).
The honest current operating point is: ship with known vulnerabilities, bound blast radius, instrument the corridor, and accept residual risk. What matters is whether teams characterize and engineer to a target failure rate, or pretend “alignment” solved a systems security problem.
Practical guidance: integrating components without root trust
The question that prompted this essay: “How do you integrate components without root trust into a system design?”
The honest answer: evaluate carefully if you should at all.
If you can’t bound blast radius, don’t ship. If you can, ship only inside a blast radius you would accept even under compromise.
Software earned trust. Software started as games, spreadsheets, things that could fail without killing anyone. And it failed. Constantly. For decades. From those failures, we developed type systems, testing, code review, deployment pipelines, rollback procedures, incident response. Every practice is scar tissue. The discipline emerged from survival. Software earned the right to be trusted.
AI skipped the runway. It arrived too impressive. Capital saw capability and said “production!” Medicine. Finance. Aviation. Legal. Now. There was no sandbox era. No decades of “let it fail safely and learn.” We’re asking a three-year-old to perform surgery because they showed precocity.
This isn’t a criticism of AI. It’s a criticism of us.
The data confirms it. MIT Project NANDA’s 2025 “GenAI Divide” report finds that ~95% of organizations see no measurable P&L impact from GenAI pilots, while ~5% extract substantial value, and highlights deployment as the sharpest separator (very few custom pilots making it to production). Source: MIT Media Lab / Project NANDA, The GenAI Divide: State of AI in Business 2025.
The failures aren’t security failures. The systems simply don’t do what they are supposed to do. The same unboundedness that makes agents unsecurable makes them unreliable. You can’t enumerate failure modes for security testing, and you can’t enumerate them for functional testing either.
Before deploying, ask two questions:
Have I discovered a use case that genuinely cannot be done any other way?
If so, is this a use case where AI can fail safely or am I putting it into a domain where failure has unacceptable consequences?
The 5% that succeed aren’t deploying “agents” into high-stakes workflows. They’re letting AI fail in bounded, reversible, low-consequence domains. That’s not the agent future everyone is selling. That’s giving AI the developmental runway that software got and we skipped.
But you’re going to do it anyway.
I know. Everyone is. So here’s how to not make it worse.
Why traditional architecture discipline breaks down:
In real engineering, when we add components, we calculate how many new failure modes the component introduces and how many tests we need to write.
An architect’s job is to keep a project in the area of least cost. Complexity grows non-linearly, but the levers we have—scope, schedule, resources—are all linear. The only way to stay in control is to know where you are on the curve.
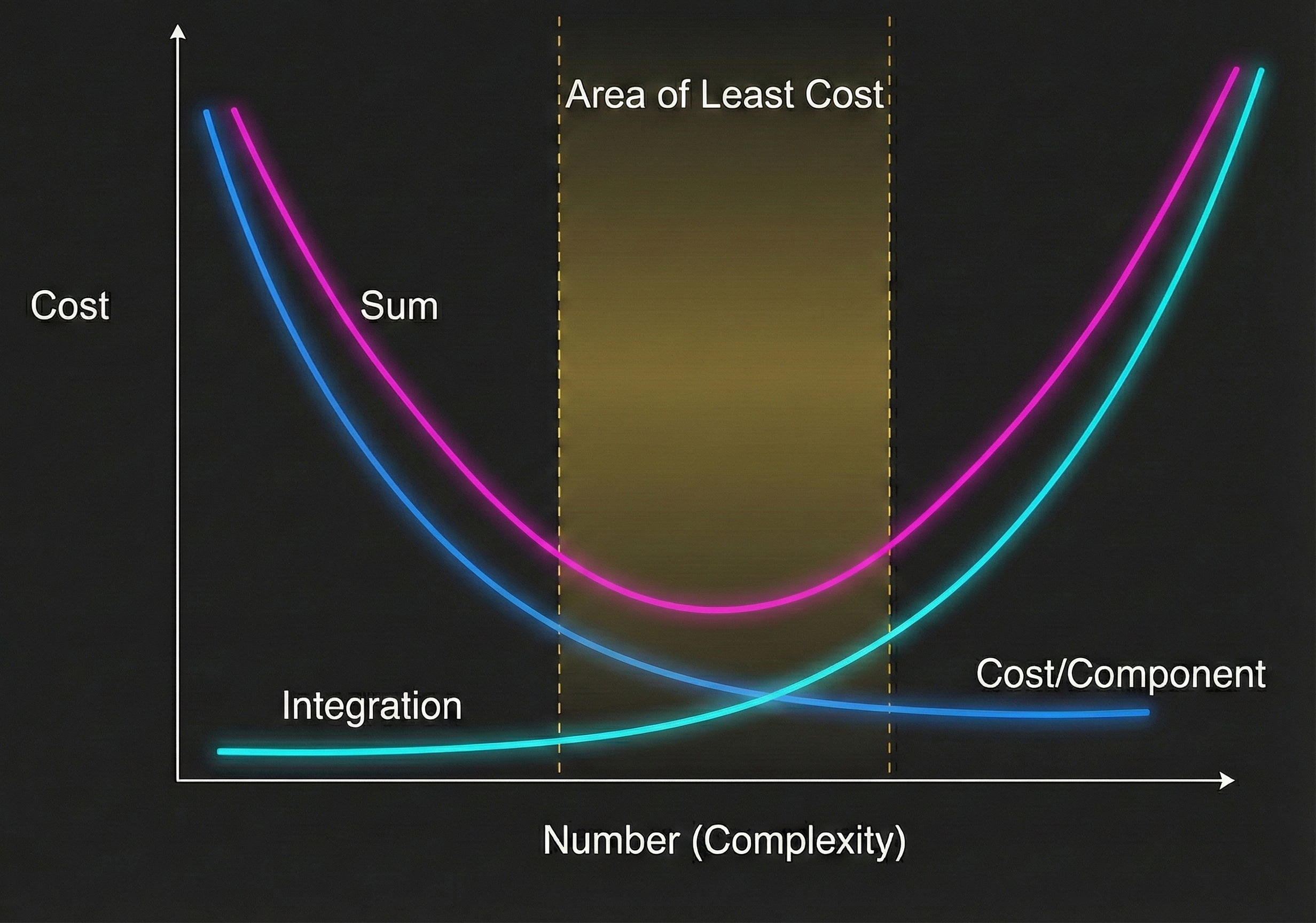
(See Löwy, Righting Software, Addison-Wesley, 2020.)
With agents, you can’t draw the curve. Add an agent and the failure modes are... what?
Language is unbounded. Counterfactuals are unbounded. You cannot enumerate them. The failures you didn’t imagine are exactly the ones the attacker will find. You’re not managing complexity. You’re accepting unknowable complexity.
This means you can’t test your way to confidence. The architectural discipline does not work here. The only lever that still works: bound the blast radius of failures you cannot enumerate.
If you don’t have a privilege-separation primitive, you cannot grant an agent authority and expect reliable governance. So don’t grant authority. Grant capability within a blast radius you’ve already accepted.
Concrete patterns:
Scope by reversibility. Agents can do things that can be undone. Drafts, not sends. Staging, not production. Proposals, not commits. The moment an action is irreversible, a human approves it or you’ve accepted that failure mode.
Credential isolation. The agent never holds credentials that exceed its blast radius. If the agent can only access a scratch database, compromise of the agent means compromise of the scratch database. Tautology as security.
Velocity limits. Bound the rate of action. An agent that can send one email per minute is annoying if compromised. An agent that can send ten thousand is a breach. You already do this for APIs. Do it for agents.
Session containment. Agent state doesn't persist across sessions by default. Persist state only via explicit, auditable checkpoints; treat persistence as an escalation. Accumulated context is a liability — it's attack surface, and memory compression introduces latent error states that manifest unpredictably downstream.
Safe defaults. Default-deny for autonomous action. When confidence is low, when monitors trip, when anything is ambiguous stop and escalate. Proceeding requires explicit permission, not the reverse.
The enterprise blocker:
None of this is what enterprises want to hear. They want “secure agents” that can be granted real authority. That product doesn’t exist yet. What exists is: agents as contractors with limited badges, operating in sandboxes, with kill switches.
If someone is selling you “trustworthy agents,” ask them where the root of trust lives. If the answer involves the word “alignment,” they don’t have one.
The honest posture:
We are shipping systems with known vulnerabilities, bounded blast radius, and residual risk we’ve decided to accept. That’s not failure. It’s engineering. The failure is pretending otherwise.
Software earned trust over decades of supervised failure. AI will too if we give it time. The question is whether we’re patient enough to give it the runway.
Appendix: Rigor Notes
R1 — Root of trust is non-bypassable enforcement
In this essay, a “root of trust” is an enforcement mechanism whose behavior cannot be rewritten by model outputs. If the model’s text can modify the policy interpreter or the authority boundary, you don’t have root trust.
R2 — Models propose plans; plan validation is structurally necessary
Generative systems act as proposal generators over actions/trajectories. This is a systems fact, not a psychological one.
R3 — Validation is set membership, not moralizing
“Valid vs invalid plan” means membership in an explicitly defined acceptability set determined by policy and product constraints.
R4 — DAG bottlenecks work only when the acceptability language is specifiable
Multi-stage restricted representations buy you safety only if membership in the permitted plan language is decidable or conservatively approximable at practical cost.
R5 — Cryptography enforces interfaces; it does not preserve semantics
Ciphertexts are pseudorandom; crypto gives integrity/authenticity and controlled interfaces. Root trust comes from keys + verification + a policy interpreter outside the model’s control.
R6 — Secrets in weights aren’t root primitives
If a secret must be usable, it exists in accessible form. “Hard to extract” is not a principled boundary; it’s a hardness assumption.
R7 — “Unreachable subspace” is not the security claim; non-perturbability is
Embedding-rank intuitions don’t yield security directly. Deep networks mix information across dimensions; reachability is a property of the whole dynamical system. The correct property is non-interference / bounded influence: user-controlled perturbations cannot materially change kernel authority state except through a trusted mediation function.
R8 — Trajectory policies differ from pointwise policies
Pointwise enforcement checks each action independently; trajectory enforcement checks path properties (cumulative budgets, escalation patterns, irreversible sequences). Pointwise checks can be trajectory-blind.
R9 — Rice’s theorem limits perfect semantic validation of arbitrary code
Undecidability results mean perfect static validation for universal code is impossible in general. Enforcement remains possible via restriction, sandboxing, mediation, monitoring, and rollback.
R10 — Economics drives escalation policies
Monitoring cost scales with the number and expense of evaluators. Real systems use cheap always-on monitors with risk-based escalation to expensive checks.
References
Geometric privilege separation (CKN):
Alioto, J.P. (2025). Cognitive Kernel Networks: Root Trust for Privilege-Separated Reasoning in High-Dimensional Models. Protocol v1.2.0. https://github.com/jpalioto/ckn_core/blob/master/docs/CKN_Whitepaper_v1_2_0.pdf
Foundational framework:
Alioto, J.P. (2025). The Fundamental Axiom of Large Language Models. Protocol v1.2.0. https://github.com/jpalioto/ckn_core/blob/master/docs/papers/The_Fundamental_Axiom_of_LLMs_v1_2_0.pdf
User-space geometric stabilization (CTN):
Alioto, J.P. (2025). Cognitive Tensor Networks: Structured Latent-Space Steering via Syntactic Constraints. Protocol v0.1.2. https://github.com/jpalioto/ctn_core
Trajectory-level governance failures (ARA):
Alioto, J.P. (2025). Ambient Reachability Attacks and the Limits of Trajectory-Level Governance. https://github.com/jpalioto/ckn_core/blob/master/docs/Ambient_Reachability_Attacks_v0_0_1.pdf
Repository: https://github.com/jpalioto/ckn_core
John P. Alioto January 2026